Tillid Interval
Hvad er tillid Interval:
Det er et skøn over en rækkevidde, der anvendes i statistikken, som indeholder en befolkningsparameter. Denne ukendte populationsparameter findes ved hjælp af en prøve model beregnet ud fra de indsamlede data .
Eksempel: gennemsnittet af en indsamlet xample kan eller måske ikke svare til den sande populations gennemsnit μ. For dette er det muligt at overveje en række prøveemner, hvor denne population betyder at være indeholdt. Jo længere dette interval, desto større er sandsynligheden for dette.
Tillidsintervallet udtrykkes som en procentdel, denomineret af konfidensniveau, hvor 90%, 95% og 99% er de mest indikerede. I billedet nedenfor har vi for eksempel et 90% konfidensinterval mellem dets øvre og nedre grænse (a og -a ).
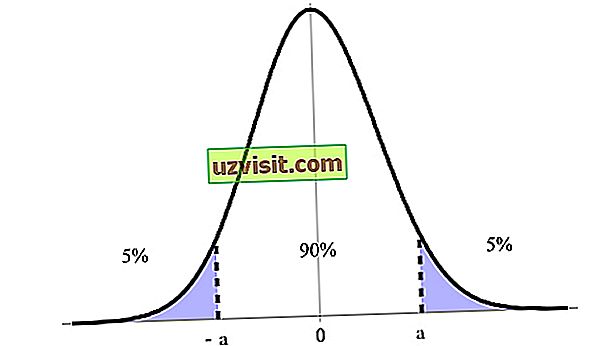
Fortrolighedsintervallet er et af de vigtigste begreber inden for hypotesetestning i statistik, fordi det bruges som et mål for usikkerhed. Udtrykket blev introduceret af polsk matematiker og statistiker Jerzy Neyman i 1937.
Hvad er relevansen af et tillidsinterval?
Tillidsintervallet er vigtigt for at angive usikkerhedsmarginen (eller upræcision) mod en beregnet beregning. Denne beregning bruger undersøgelsesprøven til at estimere den faktiske størrelse af resultatet i kildepopulationen.
Beregningen af et konfidensinterval er en strategi, der tager fat på fejlprøvetagning. Størrelsen af resultatet af dit studie og dit konfidensinterval karakteriserer de formodede værdier for den oprindelige befolkning.
Jo mindre konfidensintervallet er, desto større er sandsynligheden for, at procentdelen af undersøgelsespopulationen repræsenterer det reelle antal af kildepopulationen, hvilket giver større sikkerhed om resultatet af studieobjektet.
Hvordan fortolker man et tillidsinterval?
Den korrekte fortolkning af konfidensintervallet er nok det mest udfordrende aspekt af dette statistiske koncept. Et eksempel på den mest almindelige fortolkning af begrebet er følgende:
Der er en 95% sandsynlighed for, at den sande værdi af populationsparameteren (f.eks. Gennemsnit) i fremtiden falder i området X (nederste grænse) og Y (øvre grænse).
Fortrolighedsintervallet tolkes således som følger: Det er 95% sikker på, at intervallet mellem X (lavere bund) og Y (øvre grænse) indeholder den ægte værdi af populationsparameteren.
Det ville være helt ukorrekt at angive, at: der er en 95% sandsynlighed for, at intervallet mellem X (nedre grænse) og Y (øvre grænse) indeholder den reelle værdi af populationsparameteren.
Ovenstående erklæring er den mest almindelige misforståelse om konfidensintervallet. Når den statistiske rækkevidde er beregnet, kan den kun indeholde populationsparameteren eller ej.
Intervallerne kan dog variere mellem prøver, mens den sande populationparameter er den samme uanset prøven.
Derfor kan konfidensintervallets tillidsopgørelse kun foretages i tilfælde, hvor konfidensintervallet genberegnes for antallet af prøver.
Trinnene ved beregning af konfidensintervallet
Området beregnes ved hjælp af følgende trin:
- Indsamle prøvedataene: n ;
- Beregn prøven gennemsnit x x;
- Bestem om en populationsstandardafvigelse ( σ ) er kendt eller ukendt;
- Hvis en populationsstandardafvigelse er kendt, kan et z- punkt anvendes til det tilsvarende konfidensniveau;
- Hvis en populationsstandardafvigelse er ukendt, kan vi bruge en statistik t for det tilsvarende konfidensniveau.
- Således findes de nedre og øvre grænser for konfidensintervallet under anvendelse af følgende formler:
a) Standardafvigelse for en kendt population :
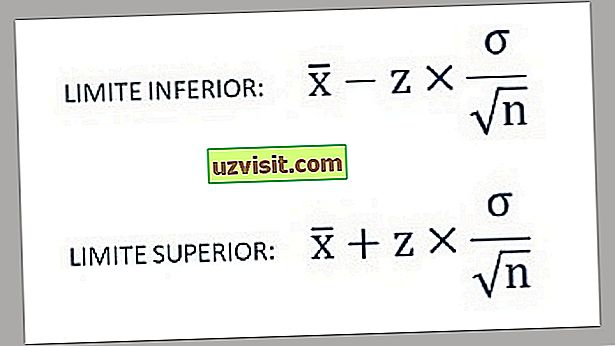
Formel til beregning af standardafvigelsen for en kendt population.
b) Standardafvigelse for en ukendt population :

Formel til beregning af standardafvigelsen for en ukendt population.
Praktisk eksempel på et konfidensinterval
En klinisk undersøgelse vurderede sammenhængen mellem tilstedeværelsen af astma og risikoen for at udvikle obstruktiv søvnapnø hos voksne.
Nogle voksne blev tilfældigt rekrutteret fra en liste over statsembedsmænd, der skulle følges i fire år.
Deltagere med astma, sammenlignet med dem uden, havde en større risiko for at udvikle apnø på fire år.
Ved udførelse af klinisk forskning som dette eksempel er en del af befolkningen af interesse normalt rekrutteret for at øge studieeffektiviteten (mindre omkostninger og mindre tid).
Denne undergruppe af enkeltpersoner, befolkningen studeret, består af dem, der opfylder inklusionskriterierne og accepterer at deltage i undersøgelsen, som vist på billedet nedenfor.

Derefter afsluttes undersøgelsen, og en effektstørrelse (for eksempel en gennemsnitlig forskel eller relativ risiko ) beregnes for at besvare forskningsspørgsmålet.
Denne proces, kaldet inference, indebærer anvendelse af data indsamlet fra undersøgelsespopulationen for at estimere størrelsen af den faktiske virkning på den berørte befolkning, det vil sige oprindelsesbefolkningen.
I det givne eksempel rekrutterede forskerne en tilfældig stikprøve af statsansatte (kildepopulation), der var berettigede og accepterede at deltage i undersøgelsen (undersøgelsespopulationen) og rapporterede, at astma øger risikoen for at udvikle apnø i undersøgelsespopulationen.
For at tage højde for en prøveudtagningsfejl som følge af rekruttering af kun en undergruppe af interessepopulationen, har de også beregnet et 95% konfidensinterval (ca. estimatet) på 1, 06 - 1, 82, hvilket indikerer en sandsynlighed for 95 % at den sande relative risiko i kildepopulationen ville være mellem 1, 06 og 1, 82 .
Tillid Interval for Gennemsnit
Når man har oplysninger om standardafvigelsen for en population, kan man beregne et konfidensinterval for gennemsnittet eller gennemsnittet af den pågældende befolkning.
Når en statistisk karakteristik, der måles (såsom indkomst, IQ, pris, højde, mængde eller vægt) er numerisk, anslås det i de fleste tilfælde, at gennemsnitsværdien for befolkningen er fundet.
Således forsøger vi at finde populationens middelværdi ( μ ) ved hjælp af en sample mean ( x )), med en fejlmargin. Resultatet af denne beregning hedder konfidensintervallet for populationens gennemsnit .
Når populationsstandardafvigelsen er kendt, er formlen for et konfidensinterval (CI) for et populationsmiddelværdi:

hvor:
- xiod er stikprøven middel;
- σ er befolkningsstandardafvigelsen;
- n er prøvestørrelsen;
- Ζ * repræsenterer den relevante værdi af standard normalfordeling for dit ønskede konfidensniveau.
Følgende er værdierne for de forskellige konfidensniveauer ( Ζ * ):
| Niveau af tillid | Værdien af Z * - |
|---|---|
| 80% | 01:28 |
| 90% | 1.645 (konventionel) |
| 95% | 1, 96 |
| 98% | 02:33 |
| 99% | 02:58 |
Tabellen ovenfor viser z * -værdier for de tilstødte konfidensniveauer. Bemærk at disse værdier er opnået fra standard normalfordelingen (Z-).
Området mellem hver z * -værdi og det negative af denne værdi er den (omtrentlige) tillidsprocent. For eksempel er området mellem z * = 1, 28 og z = -1, 28 ca. 0, 80. Derfor kan denne tabel også udvides til andre tillidsprocenter. Tabellen viser kun de mest anvendte procentueringer af tillid.
Se også betydningen af hypotesen.


